正確な値(桁)+計算した値(桁)=合計値(桁)
1台構成時の時間/10台構成時の時間
| 5.その他 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 5-1.分散処理 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 5-1-1.Hadoop | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 5-1-1.Hadoop | |||||||||||||||||||||||||||||||||||||||||||||||||||
| A.SunJavaのDL | |||||||||||||||||||||||||||||||||||||||||||||||||||
| B.SunJavaのインストール | |||||||||||||||||||||||||||||||||||||||||||||||||||
| C.リポジトリの追加 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| D.Hadoopのインストール | |||||||||||||||||||||||||||||||||||||||||||||||||||
| E.DNSやrouteの変更 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| F.Hadoopの設定 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| G.仮想マシンのテンプレート化 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| H.マスターノードの設定 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| I.スレーブノードの設定 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| J.Hadoopの実行 その1 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| K.Hadoopの実行 その2 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| L.HDFSの動作確認 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| !コメント! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Hadoopとは、Googleの基盤ソフトウェアのOSSクローンです。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Amazon型クラウド(=仮想化)とかGoogle型クラウド(=グリッド型分散処理)とか言われますが、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| とりあえず、vSphereで箱(=Amazon型クラウド)だけ作って喜んでても仕方がないので、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 箱を使って何かやってみましょうか?という観点で本項を作成しました。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| かなり乱暴な言い方ですが、とりあえず何でもいいから、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Amazon型クラウドの中でGoogle型クラウドを動かしてみよう! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| そんでもって、雲の中で何が起こっているのか体感してみよう! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| というのが本項の趣旨です。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Google型とAmazon型の違い | |||||||||||||||||||||||||||||||||||||||||||||||||||
| http://itpro.nikkeibp.co.jp/article/COLUMN/20100319/346032/?ST=system | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Google、OSS(Hadoop)基盤技術の対応関係 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| http://codezine.jp/article/detail/2448?p=1 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| A.SunJavaのDL | |||||||||||||||||||||||||||||||||||||||||||||||||||
| http://java.sun.com/javase/downloads/にて、Java SE Development Kit (JDK)の項目の、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| JDK6Update17をDLします。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ※ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 恐らく最新版でもOKだと思いますが。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| なお、SunJavaでなければダメです。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| CentOS5.4のOSインストール時、一緒にインストールするOpenJavaはNGです。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 仮想マシンのOSアーキテクチャにあったものをDLしてください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| x86の場合 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| jdk-6u17-linux-i586-rpm.bin | |||||||||||||||||||||||||||||||||||||||||||||||||||
| x86_64の場合 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| jdk-6u17-linux-x64-rpm.bin | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 今回の仮想マシン(Franz160)は、CentOS5.4 x86_64のため、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 「jdk-6u17-linux-x64-rpm.bin」となります。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| なお、DLしたbinファイルは、何かしらの方法(ftp,cifs,sshなど)で、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 仮想マシンの以下のパスにアップしておいてください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| /root/ jdk-6u17-linux-x64-rpm.bin | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ※ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| あえてフルパスを書きましたが、LinuxやPOSIX準拠OSに精通した方なら | |||||||||||||||||||||||||||||||||||||||||||||||||||
| やり方はお任せしますので、好きにやっちゃってください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 本書では便宜上、上記のパスに保存したものとして進めます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| B.SunJavaのインストール | |||||||||||||||||||||||||||||||||||||||||||||||||||
| アップしたbinファイルを確認します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# ls -Fal jdk-6u17-linux-x64-rpm.bin | |||||||||||||||||||||||||||||||||||||||||||||||||||
| -rw-r--r-- 1 root root 77636390 12月 6 04:20 jdk-6u17-linux-x64-rpm.bin | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 実行権限を付与します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# chmod 755 jdk-6u17-linux-x64-rpm.bin | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 実行権限が付与されたことを確認します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# ls -Fal jdk-6u17-linux-x64-rpm.bin | |||||||||||||||||||||||||||||||||||||||||||||||||||
| -rwxr-xr-x 1 root root 77636390 12月 6 04:20 jdk-6u17-linux-x64-rpm.bin* | |||||||||||||||||||||||||||||||||||||||||||||||||||
| binファイルを実行します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# ./jdk-6u17-linux-x64-rpm.bin | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ライセンス許諾のメッセージが表示されますので、スペースキーで進めてください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 最後に以下のように表示されたら、yesと入力すれば、インストールが開始されます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Do you agree to the above license terms? [yes or no] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 以下のような表示が出たら、最後にEnterキーを押下してDoneします。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| For more information on what data Registration collects and | |||||||||||||||||||||||||||||||||||||||||||||||||||
| how it is managed and used, see: | |||||||||||||||||||||||||||||||||||||||||||||||||||
| http://java.sun.com/javase/registration/JDKRegistrationPrivacy.html | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Press Enter to continue..... | |||||||||||||||||||||||||||||||||||||||||||||||||||
| SunJavaのVersion確認をします。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# java -version | |||||||||||||||||||||||||||||||||||||||||||||||||||
| java version "1.6.0_17" | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Java(TM) SE Runtime Environment (build 1.6.0_17-b04) | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Java HotSpot(TM) 64-Bit Server VM (build 14.3-b01, mixed mode) | |||||||||||||||||||||||||||||||||||||||||||||||||||
| C.リポジトリの追加 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| リポジトリファイルの格納ディレクトリへcdします。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# cd /etc/yum.repos.d | |||||||||||||||||||||||||||||||||||||||||||||||||||
| repoファイルをwgetします。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 yum.repos.d]# wget http://archive.cloudera.com/redhat/cdh/cloudera-testing.repo | |||||||||||||||||||||||||||||||||||||||||||||||||||
| --2010-04-15 21:10:26-- http://archive.cloudera.com/redhat/cdh/cloudera-testing.repo | |||||||||||||||||||||||||||||||||||||||||||||||||||
| archive.cloudera.com をDNSに問いあわせています... 74.82.38.64, 2001:470:0:e5::4a52:2640 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| archive.cloudera.com|74.82.38.64|:80 に接続しています... 接続しました。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| HTTP による接続要求を送信しました、応答を待っています... 200 OK | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 長さ: 218 [text/plain] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| `cloudera-testing.repo' に保存中 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 100%[================================================================>] 218 --.-K/s 時間 0s | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 2010-04-15 21:10:27 (16.0 MB/s) - `cloudera-testing.repo' へ保存完了 [218/218] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 yum.repos.d]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| D.Hadoopのインストール | |||||||||||||||||||||||||||||||||||||||||||||||||||
| yumにてHadoopをインストールします。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# yum -y install hadoop-0.20 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Loaded plugins: fastestmirror | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Loading mirror speeds from cached hostfile | |||||||||||||||||||||||||||||||||||||||||||||||||||
| * addons: rsync.atworks.co.jp | |||||||||||||||||||||||||||||||||||||||||||||||||||
| * base: rsync.atworks.co.jp | |||||||||||||||||||||||||||||||||||||||||||||||||||
| * extras: rsync.atworks.co.jp | |||||||||||||||||||||||||||||||||||||||||||||||||||
| * updates: rsync.atworks.co.jp | |||||||||||||||||||||||||||||||||||||||||||||||||||
| addons | | 951 B 00:00 | ||||||||||||||||||||||||||||||||||||||||||||||||||
| addons/primary | | 203 B 00:00 | ||||||||||||||||||||||||||||||||||||||||||||||||||
| base | | 2.1 kB 00:00 | ||||||||||||||||||||||||||||||||||||||||||||||||||
| base/primary_db | | 2.0 MB 00:00 | ||||||||||||||||||||||||||||||||||||||||||||||||||
| cloudera-testing | | 951 B 00:00 | ||||||||||||||||||||||||||||||||||||||||||||||||||
| cloudera-testing/ | | 40 kB 00:00 | ||||||||||||||||||||||||||||||||||||||||||||||||||
| cloud | 226/226 | ||||||||||||||||||||||||||||||||||||||||||||||||||
| extras | | 2.1 kB 00:00 | ||||||||||||||||||||||||||||||||||||||||||||||||||
| extras/primary_db | | 206 kB 00:00 | ||||||||||||||||||||||||||||||||||||||||||||||||||
| updates | | 1.9 kB 00:00 | ||||||||||||||||||||||||||||||||||||||||||||||||||
| updates/primary_db | | 760 kB 00:00 | ||||||||||||||||||||||||||||||||||||||||||||||||||
| Setting up Install Process | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Resolving Dependencies | |||||||||||||||||||||||||||||||||||||||||||||||||||
| --> Running transaction check | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ---> Package hadoop-0.20.noarch 0:0.20.1+169.68-1 set to be updated | |||||||||||||||||||||||||||||||||||||||||||||||||||
| --> Finished Dependency Resolution | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Dependencies Resolved | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ============================================================================================ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Package | Arch | Version | Repository | Size | |||||||||||||||||||||||||||||||||||||||||||||||
| ============================================================================================ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Installing: | |||||||||||||||||||||||||||||||||||||||||||||||||||
| hadoop-0.20 | noarch | 0.20.1+169.68-1 | cloudera-testing | 20 M | |||||||||||||||||||||||||||||||||||||||||||||||
| Transaction Summary | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ============================================================================================ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Install 1 Package(s) | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Update 0 Package(s) | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Remove 0 Package(s) | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Total download size: 20 M | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Downloading Packages: | |||||||||||||||||||||||||||||||||||||||||||||||||||
| hadoop-0.20-0.20.1+169.68-1.noarch.rpm | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Running rpm_check_debug | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Running Transaction Test | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Finished Transaction Test | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Transaction Test Succeeded | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Running Transaction | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Installing | ## | ||||||||||||||||||||||||||||||||||||||||||||||||||
| Installed: | |||||||||||||||||||||||||||||||||||||||||||||||||||
| hadoop-0.20.noarch 0:0.20.1+169.68-1 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Complete! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| E.DNSやrouteの変更 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ここから先は「The Internet」へ通信する必要はありません。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| したがって、今回の検証構成用の設定に変更します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| E-1.DNSサーバをvcs01に向けます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# vi /etc/resolv.conf | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ; generated by /sbin/dhclient-script | |||||||||||||||||||||||||||||||||||||||||||||||||||
| nameserver 192.168.11.1 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ↓変更 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| nameserver 192.168.11.96 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| E-2.DefaultGWアドレスを192.168.11.254へ向けます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# vi /etc/sysconfig/network | |||||||||||||||||||||||||||||||||||||||||||||||||||
| NETWORKING=yes | |||||||||||||||||||||||||||||||||||||||||||||||||||
| NETWORKING_IPV6=no | |||||||||||||||||||||||||||||||||||||||||||||||||||
| HOSTNAME=Franz160.luxion.biz | |||||||||||||||||||||||||||||||||||||||||||||||||||
| GATEWAY=192.168.11.1 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ↓変更 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| GATEWAY=192.168.11.254 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| !コメント! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 上記でホスト名も変更できます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| テンプレートからデプロイした後に変更しますので覚えておきましょう。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| E-3.Hostsファイルの設定を変更します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# vi /etc/hosts | |||||||||||||||||||||||||||||||||||||||||||||||||||
| # Do not remove the following line, or various programs | |||||||||||||||||||||||||||||||||||||||||||||||||||
| # that require network functionality will fail. | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 127.0.0.1 Franz160.luxion.biz Franz160 localhost.localdomain localhost | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ::1 localhost6.localdomain6 localhost6 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ↓変更 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 127.0.0.1 localhost.localdomain localhost | |||||||||||||||||||||||||||||||||||||||||||||||||||
| !コメント! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 取り急ぎ、上記設定に従ってください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 名前解決の順番を変更したりetcやり方はいくつかありますが、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Hadoopサービスが起動した後、待ち受けIPアドレスが127.0.0.1になるなどの | |||||||||||||||||||||||||||||||||||||||||||||||||||
| いくつかの弊害が出てくるため、今回の構成における原則として、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 「名前解決は必ずDNSサーバにて実施する」とします。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| E-4.念のため、networkサービスをrestartしておきましょう。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# /etc/rc.d/init.d/network restart | |||||||||||||||||||||||||||||||||||||||||||||||||||
| インターフェース eth0 を終了中: [ OK ] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ループバックインターフェースを終了中 [ OK ] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ループバックインターフェイスを呼び込み中 [ OK ] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| インターフェース eth0 を活性化中: [ OK ] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| E-5.routeとlookupの確認をしておきましょう。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| E-5-1.まずはrouteの確認から実施します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# route | |||||||||||||||||||||||||||||||||||||||||||||||||||
| もしくは | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# netstat –r | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Kernel IP routing table | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Destination Gateway Genmask Flags Metric Ref Use Iface | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 192.168.11.0 * 255.255.255.0 U 0 0 0 eth0 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 169.254.0.0 * 255.255.0.0 U 0 0 0 eth0 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| default 192.168.11.254 0.0.0.0 UG 0 0 0 eth0 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| E-5-2.次にlookupの確認を実施します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# nslookup franz160 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Server: 192.168.11.96 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Address: 192.168.11.96#53 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Name: franz160.luxion.biz | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Address: 192.168.11.160 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| F.Hadoopの設定 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| F-1.設定ディレクトリの作成 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# cp -r /etc/hadoop-0.20/conf.empty /etc/hadoop-0.20/conf.test1 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# alternatives --install /etc/hadoop-0.20/conf hadoop-0.20-conf /etc/hadoop-0.20/conf.test1 20 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| F-2.設定ディレクトリの確認 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# alternatives --display hadoop-0.20-conf | |||||||||||||||||||||||||||||||||||||||||||||||||||
| hadoop-0.20-conf -ステータスは自動です。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| リンクは現在 /etc/hadoop-0.20/conf.test1 を指しています。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| /etc/hadoop-0.20/conf.empty - 優先項目 10 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| /etc/hadoop-0.20/conf.test1 - 優先項目 20 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 現在の「最適」バージョンは /etc/hadoop-0.20/conf.test1 です。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| F-3.設定ファイルの編集 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| F-3-1.mastersファイルの設定 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# cd /etc/hadoop-0.20/conf.test1 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# echo Franz160.luxion.biz > masters | |||||||||||||||||||||||||||||||||||||||||||||||||||
| F-3-2.slavesファイルの設定 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# cat << EOF > slaves | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > Franz164.luxion.biz | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > Franz165.luxion.biz | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > Franz166.luxion.biz | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > Franz167.luxion.biz | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > Franz168.luxion.biz | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > Franz169.luxion.biz | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > Franz170.luxion.biz | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > Franz171.luxion.biz | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > Franz172.luxion.biz | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > Franz173.luxion.biz | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > EOF | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| F-3-3.hadoop-env.shファイルの設定 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# vi hadoop-env.sh | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Set Hadoop-specific environment variables here. | |||||||||||||||||||||||||||||||||||||||||||||||||||
| # The only required environment variable is JAVA_HOME. All others are | |||||||||||||||||||||||||||||||||||||||||||||||||||
| # optional. When running a distributed configuration it is best to | |||||||||||||||||||||||||||||||||||||||||||||||||||
| # set JAVA_HOME in this file, so that it is correctly defined on | |||||||||||||||||||||||||||||||||||||||||||||||||||
| # remote nodes. | |||||||||||||||||||||||||||||||||||||||||||||||||||
| # The java implementation to use. Required. | |||||||||||||||||||||||||||||||||||||||||||||||||||
| # export JAVA_HOME=/usr/lib/j2sdk1.5-sun | |||||||||||||||||||||||||||||||||||||||||||||||||||
| export JAVA_HOME=/usr/java/default | |||||||||||||||||||||||||||||||||||||||||||||||||||
| F-3-4.core-site.xmlファイルの設定 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# cat << EOF > core-site.xml | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > <configuration> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > <property> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > <name>fs.default.name</name> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > <value>hdfs://Franz160.luxion.biz:8020</value> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > </property> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > </configuration> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > EOF | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| F-3-5.hdfs-site.xmlの設定 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# cat << EOF > hdfs-site.xml | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > <configuration> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > <property> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > <name>dfs.replication</name> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > <value>10</value> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > </property> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > </configuration> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > EOF | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| !コメント! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| <value>10</value>は、スレーブノードにレプリケーションする数を設定しています。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 今回はスレーブノードを10台まで増やしますので10としました。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノードが少ない分には問題ありませんが、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 多い場合に全ノードにてこの値を増やす必要があります。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 現在の設定の場合、11台目を追加してもマスターノードにて認識はしますが、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| レプリケーションはしません=処理速度の向上には寄与しません。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| F-3-6.mapred-site.xmlファイルの設定 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# cat << EOF > mapred-site.xml | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > <configuration> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > <property> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > <name>mapred.job.tracker</name> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > <value>Franz160.luxion.biz:8021</value> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > </property> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > </configuration> | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > EOF | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| G.仮想マシンのテンプレート化 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ここで一旦、仮想マシンをshutdownしテンプレート化してしまいましょう。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| この後は、マスターノード*1台、スレーブノード*1台の構成で、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| まずはHadoopが正常動作することを確認します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| その後、スレーブノードを10台まで増やしますので、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| テンプレートからのデプロイをする方が後々楽になります。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| H.マスターノードの設定 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| テンプレートからデプロイした後、まずはIPアドレスを変更してください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 今回の構成では、「192.168.11.160」になります。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| その後、上記「5.DNSやrouteの変更」を確認&必要に応じて設定変更し一度Rebootしてください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| H-1.HDFSフォーマット | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# sudo -u hadoop hadoop-0.20 namenode -format | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 08:25:46 INFO namenode.NameNode: STARTUP_MSG: | |||||||||||||||||||||||||||||||||||||||||||||||||||
| /************************************************************ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| STARTUP_MSG: Starting NameNode | |||||||||||||||||||||||||||||||||||||||||||||||||||
| STARTUP_MSG: host = Franz160.luxion.biz/192.168.11.174 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| STARTUP_MSG: args = [-format] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| STARTUP_MSG: version = 0.20.1+169.68 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| STARTUP_MSG: build = -r c78aed9266941644c7704c3429e5fcb6466c13d9; compiled by 'root' on Mon Mar 22 02:21:38 EDT 2010 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ************************************************************/ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 08:25:46 INFO namenode.FSNamesystem: fsOwner=hadoop,hadoop | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 08:25:46 INFO namenode.FSNamesystem: supergroup=supergroup | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 08:25:46 INFO namenode.FSNamesystem: isPermissionEnabled=true | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 08:25:46 INFO common.Storage: Image file of size 96 saved in 0 seconds. | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 08:25:46 INFO common.Storage: Storage directory /tmp/hadoop-hadoop/dfs/name has been successfully formatted. | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 08:25:46 INFO namenode.NameNode: SHUTDOWN_MSG: | |||||||||||||||||||||||||||||||||||||||||||||||||||
| /************************************************************ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| SHUTDOWN_MSG: Shutting down NameNode at Franz160.luxion.biz/192.168.11.174 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ************************************************************/ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| H-2.Hadoopサービスの起動 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz174 conf.test1]# service hadoop-0.20-namenode start | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Starting Hadoop namenode daemon (hadoop-namenode): starting namenode, | |||||||||||||||||||||||||||||||||||||||||||||||||||
| logging to /usr/lib/hadoop-0.20/bin/../logs/hadoop-hadoop-namenode-Franz174.luxion.biz.out | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [ OK ] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz174 conf.test1]# service hadoop-0.20-jobtracker start | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Starting Hadoop jobtracker daemon (hadoop-jobtracker): starting jobtracker, | |||||||||||||||||||||||||||||||||||||||||||||||||||
| logging to /usr/lib/hadoop-0.20/bin/../logs/hadoop-hadoop-jobtracker-Franz174.luxion.biz.out | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [ OK ] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz174 conf.test1]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| H-3.Hadoopサービスの確認 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# netstat -ant | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Active Internet connections (servers and established) | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Proto Recv-Q Send-Q Local Address Foreign Address State | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 0.0.0.0:655 0.0.0.0:* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 :::50030 :::* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 ::ffff:192.168.11.160:8020 :::* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 ::ffff:192.168.11.160:8021 :::* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 :::50070 :::* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 :::22 :::* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 :::53306 :::* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 :::43132 :::* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 ::ffff:192.168.11.160:8020 ::ffff:192.168.11.160:38940 ESTABLISHED | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 132 ::ffff:192.168.11.160:22 ::ffff:192.168.11.11:39858 ESTABLISHED | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 ::ffff:192.168.11.160:38940 ::ffff:192.168.11.160:8020 ESTABLISHED | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| !コメント! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| TCP:50030とTCP:50070がWeb管理画面のPort番号です。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| TCP:8020とTCP:8021にスレーブノードがアクセスしてきます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| H-4.HadoopのWeb管理画面確認 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| H-4-1.MapReduceのWeb管理画面 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ブラウザを開いて以下のURLにアクセスしてください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
http://192.168.11.160:50030/ | ||||||||||||||||||||||||||||||||||||||||||||||||||
| H-4-2.HDFS のWeb管理画面 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ブラウザを開いて以下のURLにアクセスしてください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
http://192.168.11.160:50070/ | ||||||||||||||||||||||||||||||||||||||||||||||||||
| I.スレーブノードの設定 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| テンプレートからデプロイした後、まずはIPアドレスを変更してください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 今回の構成では「Franz164=192.168.11.164」になります。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| その後、上記「5.DNSやrouteの変更」を確認&必要に応じて設定変更し一度Rebootしてください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| I-1.Hadoopサービスの起動 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz164 conf.test1]# service hadoop-0.20-datanode start | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Starting Hadoop datanode daemon (hadoop-datanode): starting datanode, | |||||||||||||||||||||||||||||||||||||||||||||||||||
| logging to /usr/lib/hadoop-0.20/bin/../logs/hadoop-hadoop-datanode-Franz164.luxion.biz.out | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [ OK ] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz164 conf.test1]# service hadoop-0.20-tasktracker start | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Starting Hadoop tasktracker daemon (hadoop-tasktracker): starting tasktracker, | |||||||||||||||||||||||||||||||||||||||||||||||||||
| logging to /usr/lib/hadoop-0.20/bin/../logs/hadoop-hadoop-tasktracker-Franz164.luxion.biz.out | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [ OK ] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz164 conf.test1]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| !コメント! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| マスターノードとサービス名が異なっていることに注意してください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| マスターノードのサービス | |||||||||||||||||||||||||||||||||||||||||||||||||||
| service hadoop-0.20-namenode start | |||||||||||||||||||||||||||||||||||||||||||||||||||
| service hadoop-0.20-jobtracker start | |||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノードのサービス | |||||||||||||||||||||||||||||||||||||||||||||||||||
| service hadoop-0.20-datanode start | |||||||||||||||||||||||||||||||||||||||||||||||||||
| service hadoop-0.20-tasktracker start | |||||||||||||||||||||||||||||||||||||||||||||||||||
| I-2.Hadoopサービスの確認 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz164 conf.test1]# netstat -ant | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Active Internet connections (servers and established) | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Proto Recv-Q Send-Q Local Address Foreign Address State | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 0.0.0.0:649 0.0.0.0:* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 ::ffff:127.0.0.1:54466 :::* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 :::50020 :::* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 :::50060 :::* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 :::22 :::* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 :::50010 :::* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 :::50075 :::* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 :::33403 :::* LISTEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 ::ffff:192.168.11.164:57066 ::ffff:192.168.11.160:8021 ESTABLISHED | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 0 ::ffff:192.168.11.164:33368 ::ffff:192.168.11.160:8020 ESTABLISHED | |||||||||||||||||||||||||||||||||||||||||||||||||||
| tcp 0 132 ::ffff:192.168.11.164:22 ::ffff:192.168.11.11:39896 ESTABLISHED | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz164 conf.test1]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| !コメント! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| マスターノードのTCP:8020とTCP:8021にアクセスしていればOKです。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| あとはTCP:50010,50020,50060,50075がListenしていればOKでしょう。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
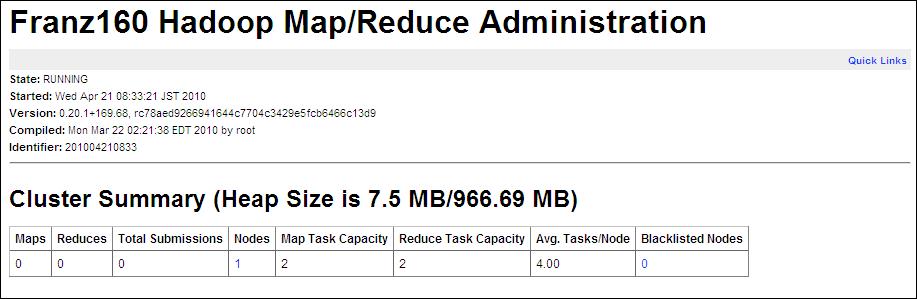
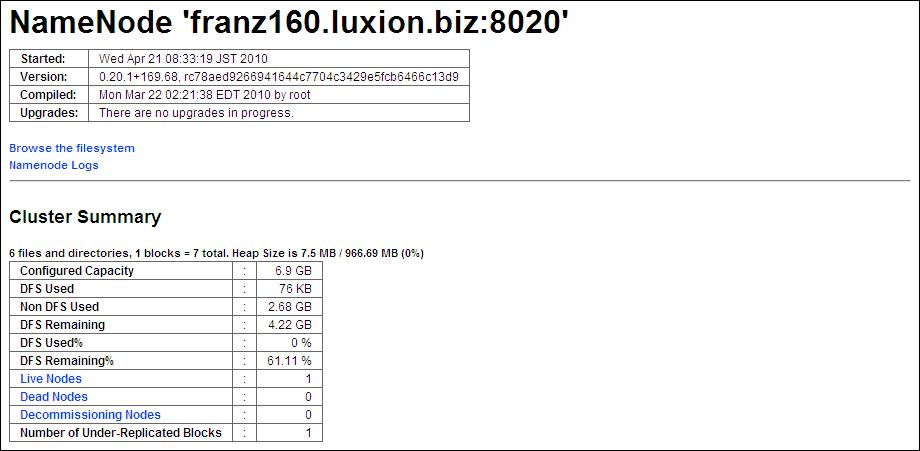
| I-3.HadoopのWeb管理画面確認 その2 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| もう一度ブラウザを開いて以下のURLにアクセスしてください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
http://192.168.11.160:50030/ | ||||||||||||||||||||||||||||||||||||||||||||||||||
| !コメント! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Nodes=1、MapTaskCapacity&ReduceTaskCapacity=2となっています。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
http://192.168.11.160:50070/ | ||||||||||||||||||||||||||||||||||||||||||||||||||
| !コメント! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Live Nodes=1となっています。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| J.Hadoopの実行 その1 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| π(円周率)を計算するサンプルプログラムを実行してみます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# sudo -u hadoop hadoop-0.20 jar /usr/lib/hadoop-0.20/hadoop-*-examples.jar pi 20 2000 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Number of Maps = 20 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Samples per Map = 2000 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #0 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #1 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #2 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #3 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #4 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #5 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #6 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #7 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #8 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #9 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #10 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #11 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #12 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #13 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #14 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #15 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #16 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #17 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #18 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #19 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Starting Job | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:03:03 INFO mapred.FileInputFormat: Total input paths to process : 20 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:03:04 INFO mapred.JobClient: Running job: job_201004210833_0001 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:03:06 INFO mapred.JobClient: map 0% reduce 0% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:03:33 INFO mapred.JobClient: map 5% reduce 0% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:03:36 INFO mapred.JobClient: map 10% reduce 0% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:03:42 INFO mapred.JobClient: map 15% reduce 0% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:03:45 INFO mapred.JobClient: map 20% reduce 5% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:03:48 INFO mapred.JobClient: map 25% reduce 5% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:03:55 INFO mapred.JobClient: map 30% reduce 5% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:03:58 INFO mapred.JobClient: map 40% reduce 8% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:04:04 INFO mapred.JobClient: map 50% reduce 8% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:04:09 INFO mapred.JobClient: map 50% reduce 13% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:04:15 INFO mapred.JobClient: map 55% reduce 16% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:04:27 INFO mapred.JobClient: map 60% reduce 16% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:04:36 INFO mapred.JobClient: map 70% reduce 16% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:04:39 INFO mapred.JobClient: map 70% reduce 20% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:04:45 INFO mapred.JobClient: map 80% reduce 23% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:04:51 INFO mapred.JobClient: map 85% reduce 23% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:04:54 INFO mapred.JobClient: map 90% reduce 23% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:04:57 INFO mapred.JobClient: map 95% reduce 28% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:00 INFO mapred.JobClient: map 100% reduce 30% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:03 INFO mapred.JobClient: map 100% reduce 33% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:09 INFO mapred.JobClient: map 100% reduce 100% | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Job complete: job_201004210833_0001 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Counters: 18 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Job Counters | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Launched reduce tasks=1 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Launched map tasks=20 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Data-local map tasks=20 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: FileSystemCounters | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: FILE_BYTES_READ=446 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: HDFS_BYTES_READ=2360 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: FILE_BYTES_WRITTEN=1646 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=215 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Map-Reduce Framework | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Reduce input groups=40 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Combine output records=0 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Map input records=20 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Reduce shuffle bytes=560 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Reduce output records=0 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Spilled Records=80 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Map output bytes=360 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Map input bytes=480 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Combine input records=0 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Map output records=40 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/21 09:05:12 INFO mapred.JobClient: Reduce input records=40 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Job Finished in 128.812 seconds | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Estimated value of Pi is 3.14140000000000000000 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 conf.test1]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| !コメント! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 投入した以下のコマンドのうち、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| sudo -u hadoop hadoop-0.20 jar /usr/lib/hadoop-0.20/hadoop-*-examples.jar pi 20 2000 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 20=Mapの数(今回の構成ではスレーブノード数*2の倍数) | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 2000=πの精度 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| となっているようです。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| K.Hadoopの実行 その2 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| π(円周率)を計算するサンプルプログラムをHadoopっぽく実行してみます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| その1で実行したコマンド | |||||||||||||||||||||||||||||||||||||||||||||||||||
| sudo -u hadoop hadoop-0.20 jar /usr/lib/hadoop-0.20/hadoop-*-examples.jar pi 20 2000 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 今回実行するコマンド | |||||||||||||||||||||||||||||||||||||||||||||||||||
| sudo -u hadoop hadoop-0.20 jar /usr/lib/hadoop-0.20/hadoop-*-examples.jar pi 20 2000000000 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 理論上はスレーブノードが増えていくにつれて、処理速度が向上するらしいので、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| こちらの確認も実施します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| K-1.サービスの停止 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 「J.Hadoopの実行 その1」で、Franz160とFranz164にてHadoopを実行していますが | |||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノードを増やしていくため、一旦サービスを停止します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| マスターノード | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# service hadoop-0.20-namenode stop | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Stopping Hadoop namenode daemon (hadoop-namenode): stopping namenode | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [ OK ] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# service hadoop-0.20-jobtracker stop | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Stopping Hadoop jobtracker daemon (hadoop-jobtracker): stopping jobtracker | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [ OK ] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz164 ~]# service hadoop-0.20-datanode stop | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Stopping Hadoop datanode daemon (hadoop-datanode): datanode to stop | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [ OK ] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz164 ~]# service hadoop-0.20-tasktracker stop | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Stopping Hadoop tasktracker daemon (hadoop-tasktracker): tasktracker to stop | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [ OK ] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| K-2.ゴミディレクトリ&ファイルの消去 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 知らないよりは知っていたほうが良いレベルのコマンドです。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノードを10台目まで追加していく際、手順を間違えたりすると、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ・マスターノードがスレーブノードを認識しなくなる | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ・一部のサービスが正常に起動しなくなる | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ・サンプルプログラムを実行した際にJAVAのエラーが表示される | |||||||||||||||||||||||||||||||||||||||||||||||||||
| といった事象に遭遇することがあります。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| この事象を回避するため、おまじない的なコマンドとして投入してください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ※ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 私がこの方法で上記事象を回避するまでに要した時間は聞かないでください。。。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| マスターノード | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# rm -rf /tmp/Jetty_0_0_0_0_500* | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# rm -rf /tmp/h* | |||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz164 ~]# rm -rf /tmp/Jetty_0_0_0_0_500* | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz164 ~]# rm -rf /tmp/h* | |||||||||||||||||||||||||||||||||||||||||||||||||||
| !コメント! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ちなみに何を消去しているか?について、以下の補足しておきます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| サービス開始やサンプルプログラムを実行すると、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| /tmp配下にHadoop関連のディレクトリが、以下のようなイメージで作成されます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| マスターノード | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# ls -Fal /tmp | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 合計 72 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxrwxrwt 8 root root 4096 4月 22 06:59 ./ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxr-xr-x 24 root root 4096 4月 22 05:38 ../ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxrwxrwt 2 root root 4096 4月 22 05:38 .ICE-unix/ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxrwxrwt 2 root root 4096 4月 22 05:38 .font-unix/ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| -rw------- 1 root root 1024 4月 17 06:33 .rnd | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxrwxr-x 3 hadoop hadoop 4096 4月 22 06:59 Jetty_0_0_0_0_50030_job____yn7qmk/ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxrwxr-x 3 hadoop hadoop 4096 4月 22 06:59 Jetty_0_0_0_0_50070_hdfs____w2cu08/ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxr-xr-x 3 hadoop hadoop 4096 4月 22 06:59 hadoop-hadoop/ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxr-xr-x 2 hadoop hadoop 4096 4月 22 07:00 hsperfdata_hadoop/ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz164 ~]# ls -Fal /tmp | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 合計 72 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxrwxrwt 8 root root 4096 4月 22 06:59 ./ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxr-xr-x 23 root root 4096 4月 22 05:38 ../ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxrwxrwt 2 root root 4096 4月 22 05:38 .ICE-unix/ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxrwxrwt 2 root root 4096 4月 22 05:39 .font-unix/ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| -rw------- 1 root root 1024 4月 17 06:33 .rnd | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxrwxr-x 3 hadoop hadoop 4096 4月 22 06:59 Jetty_0_0_0_0_50060_task____.2vcltf/ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxrwxr-x 3 hadoop hadoop 4096 4月 22 06:59 Jetty_0_0_0_0_50075_datanode____hwtdwq/ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxrwxr-x 4 hadoop hadoop 4096 4月 22 06:59 hadoop-hadoop/ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxr-xr-x 2 hadoop hadoop 4096 4月 22 07:00 hsperfdata_hadoop/ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| これらのディレクトリは、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ・サービス再起動 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ・OS再起動 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ・HDFSのフォーマット | |||||||||||||||||||||||||||||||||||||||||||||||||||
| では消去されず、いつまでの残ってしまいます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| サービス起動の順序やスレーブノード追加手順を間違えると、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 上記ディレクトリ内のファイルに不整合が生じるようで、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 「K-2.ゴミファイルの消去」の冒頭に記載した事象に遭遇します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| このため、以下の手順にて対処することにより、冒頭の事象を回避することができます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| サービス停止→ゴミディレクトリ&ファイル消去→サービス開始 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ちなみに、ゴミディレクトリ&ファイル消去を実施しても、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| サービスを開始すると、新たに生成されるため全く問題ありません。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| K-3.スレーブノードの追加 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 「G.仮想マシンのテンプレート化」にて、仮想マシンをテンプレート化しました。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| このテンプレートから以下のようにスレーブノードを10台目までデプロイしてください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| また、必要に応じて「5.DNSやrouteの変更」を実施してください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| マスターノード | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Franz160=192.168.11.160 | ←既に作成済み | ||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Franz164=192.168.11.164 1台目 | ←既に作成済み | ||||||||||||||||||||||||||||||||||||||||||||||||||
| Franz165=192.168.11.165 2台目 | ←この2台目から10台目までをデプロイしていく | ||||||||||||||||||||||||||||||||||||||||||||||||||
| Franz166=192.168.11.166 3台目 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Franz167=192.168.11.167 4台目 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Franz168=192.168.11.168 5台目 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Franz169=192.168.11.169 6台目 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Franz170=192.168.11.170 7台目 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Franz171=192.168.11.171 8台目 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Franz172=192.168.11.172 9台目 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Franz173=192.168.11.173 10台目 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| K-4.サービスの開始(補足) | |||||||||||||||||||||||||||||||||||||||||||||||||||
| マスターノードのみHDFSをフォーマットした後にサービスを開始します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| また、スレーブノードにてサービス開始後、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 「I-2.Hadoopサービスの確認」や「I-3.HadoopのWeb管理画面確認 その2」にて、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノードが追加されない場合は、「K-2.ゴミディレクトリ&ファイルの消去」を | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 実施してみてください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 「K-2.ゴミディレクトリ&ファイルの消去」実施の流れとしては、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ・マスター&全スレーブのサービス停止 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ・マスター&全スレーブのゴミディレクトリ&ファイル消去 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| を実施した後、下記に示す通り、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ・マスターのHDFSフォーマット | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ・マスターのサービス開始 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ・スレーブのサービスを順に開始 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| とすれば、まず間違いなく成功します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| K-5.マスターノードのHDFSフォーマット | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# sudo -u hadoop hadoop-0.20 namenode -format | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/22 07:33:34 INFO namenode.NameNode: STARTUP_MSG: | |||||||||||||||||||||||||||||||||||||||||||||||||||
| /************************************************************ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| STARTUP_MSG: Starting NameNode | |||||||||||||||||||||||||||||||||||||||||||||||||||
| STARTUP_MSG: host = Franz160.luxion.biz/192.168.11.160 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| STARTUP_MSG: args = [-format] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| STARTUP_MSG: version = 0.20.1+169.68 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| STARTUP_MSG: build = -r c78aed9266941644c7704c3429e5fcb6466c13d9; compiled by 'root' on Mon Mar 22 02:21:38 EDT 2010 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ************************************************************/ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/22 07:33:35 INFO namenode.FSNamesystem: fsOwner=hadoop,hadoop | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/22 07:33:35 INFO namenode.FSNamesystem: supergroup=supergroup | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/22 07:33:35 INFO namenode.FSNamesystem: isPermissionEnabled=true | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/22 07:33:35 INFO common.Storage: Image file of size 96 saved in 0 seconds. | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/22 07:33:35 INFO common.Storage: Storage directory /tmp/hadoop-hadoop/dfs/name has been successfully formatted. | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/22 07:33:35 INFO namenode.NameNode: SHUTDOWN_MSG: | |||||||||||||||||||||||||||||||||||||||||||||||||||
| /************************************************************ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| SHUTDOWN_MSG: Shutting down NameNode at Franz160.luxion.biz/192.168.11.160 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ************************************************************/ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| K-6.マスターノードのサービス開始 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# service hadoop-0.20-namenode start | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Starting Hadoop namenode daemon (hadoop-namenode): starting namenode, | |||||||||||||||||||||||||||||||||||||||||||||||||||
| logging to /usr/lib/hadoop-0.20/bin/../logs/hadoop-hadoop-namenode-Franz160.luxion.biz.out | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [ OK ] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# service hadoop-0.20-jobtracker start | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Starting Hadoop jobtracker daemon (hadoop-jobtracker): starting jobtracker, | |||||||||||||||||||||||||||||||||||||||||||||||||||
| logging to /usr/lib/hadoop-0.20/bin/../logs/hadoop-hadoop-jobtracker-Franz160.luxion.biz.out | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [ OK ] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| K-7.スレーブノード1台目のサービス開始 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz164 ~]# service hadoop-0.20-datanode start | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Starting Hadoop datanode daemon (hadoop-datanode): starting datanode, | |||||||||||||||||||||||||||||||||||||||||||||||||||
| logging to /usr/lib/hadoop-0.20/bin/../logs/hadoop-hadoop-datanode-Franz164.luxion.biz.out | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [ OK ] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz164 ~]# service hadoop-0.20-tasktracker start | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Starting Hadoop tasktracker daemon (hadoop-tasktracker): starting tasktracker, | |||||||||||||||||||||||||||||||||||||||||||||||||||
| logging to /usr/lib/hadoop-0.20/bin/../logs/hadoop-hadoop-tasktracker-Franz164.luxion.biz.out | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [ OK ] | |||||||||||||||||||||||||||||||||||||||||||||||||||
| K-8.サンプルプログラムの実行 1回目結果 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| マスターノードにて、以下のコマンドを実行します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# sudo -u hadoop hadoop-0.20 jar /usr/lib/hadoop-0.20/hadoop-*-examples.jar pi 20 2000000000 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Number of Maps = 20 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Samples per Map = 2000000000 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #0 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wrote input for Map #1 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 一 部 省 略 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜・〜 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/19 23:30:27 INFO mapred.JobClient: Combine input records=0 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/19 23:30:27 INFO mapred.JobClient: Map output records=40 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 10/04/19 23:30:27 INFO mapred.JobClient: Reduce input records=40 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Job Finished in 2443.619 seconds | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Estimated value of Pi is 3.14159267580000000000 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 上記結果の通り、スレーブノード1台構成時、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 小数点以下7桁までの計算に2443秒=40分掛かりました。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| この後はスレーブノードを1台追加するごとに上記の時間を計測していきます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| なお、スレーブノード2台目以降を追加する場合は、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 上記「K-7.スレーブノード1台目のサービス開始」を順次実施してください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| K-9.サンプルプログラムの実行 2回目以降の結果 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 以下、結果のみ記載します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード10台構成時 | 378.015 seconds | ||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード9台構成時 | 508.309 seconds | ||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード8台構成時 | 499.248 seconds | ||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード7台構成時 | 498.607 seconds | ||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード6台構成時 | 495.314 seconds | ||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード5台構成時 | 495.274 seconds | ||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード4台構成時 | 727.006 seconds | ||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード3台構成時 | 969.464 seconds | ||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード2台構成時 | 1231.21 seconds | ||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード1台構成時 | 2443.619 seconds | ||||||||||||||||||||||||||||||||||||||||||||||||||
| !コメント! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード5台目〜9台目の結果が不甲斐無いですが、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 最後の10台目はきっちり結果を出しています。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| また、1台目と10台目で所要時間を比較すると、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| パフォーマンスはおよそ6.5倍向上しています。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ちなみに、パフォーマンスは向上していますが、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 絶対的な物理リソース(物理CPUや物理メモリ)は増やしていません。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 仮想マシンを追加しただけなので。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| K-10.その他の結果 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 計算精度=データ容量 | 200000 | 20000000 | 200000000 | 2000000000 | |||||||||||||||||||||||||||||||||||||||||||||||
| 赤字は正確な円周率の値 | 3.141604 | 3.1415933 | 3.141592629 | 3.1415926758 | |||||||||||||||||||||||||||||||||||||||||||||||
| 小数点以下の桁数 正確な値(桁)+計算した値(桁)=合計値(桁) |
3桁+3桁=6桁 | 5桁+2桁=7桁 | 7桁+2桁=9桁 | 7桁+3桁=10桁 | |||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード10台構成時(単位=秒) | 31.305 | 34.274 | 63.706 | 378.015 | |||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード9台構成時(単位=秒) | 31.183 | 38.181 | 97.502 | 508.309 | |||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード8台構成時(単位=秒) | 38.147 | 39.176 | 91.536 | 499.248 | |||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード7台構成時(単位=秒) | 38.102 | 41.137 | 87.398 | 498.607 | |||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード6台構成時(単位=秒) | 38.073 | 42.357 | 92.376 | 495.314 | |||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード5台構成時(単位=秒) | 39.772 | 44.768 | 90.282 | 495.274 | |||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード4台構成時(単位=秒) | 51.245 | 46.087 | 156.814 | 727.006 | |||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード3台構成時(単位=秒) | 58.325 | 61.365 | 137.549 | 969.464 | |||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード2台構成時(単位=秒) | 65.304 | 72.36 | 208.182 | 1231.21 | |||||||||||||||||||||||||||||||||||||||||||||||
| スレーブノード1台構成時(単位=秒) | 96.216 | 162.212 | 382.469 | 2443.619 | |||||||||||||||||||||||||||||||||||||||||||||||
| パフォーマンス(単位=倍) 1台構成時の時間/10台構成時の時間 |
3.1 | 4.7 | 6.0 | 6.5 | |||||||||||||||||||||||||||||||||||||||||||||||
| !コメント1! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 上記K-9のコメントにも記載した通りですが、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 1.処理するデータ容量が増える | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 2.スレーブノード数が増える(物理リソースが増えていないことに着目) | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ことによって、パフォーマンスが向上しているようです。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| !コメント2! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 言わずもがな、純粋に円周率だけ算出したいのであれば、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| もっと優秀なアプリケーションはたくさんあります。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| (万単位の桁数をゴリゴリ計算してくれるようなアプリです。) | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 今回はデータ容量とスレーブノードを増やした場合の処理時間を確認するため、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 円周率算出のサンプルプログラムを使用した次第です。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| L.HDFSの動作確認 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| HDFS=Hadoop Distributed File Systemの略ですが、Hadoop用に開発されたPB(ペタバイト)クラスまで | |||||||||||||||||||||||||||||||||||||||||||||||||||
| スケールするように設計されたファイルシステムです。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 要するにファイルシステムなので、ls,mv,cp,rm,cat,mkdir,chmod,chownなどのコマンドが使えます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| L-1.ディレクトリ作成&chown | |||||||||||||||||||||||||||||||||||||||||||||||||||
| root用のディレクトリを作成した後、chownにて作成したディレクトリのオーナーをrootに変更します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# sudo -u hadoop hadoop-0.20 fs -mkdir /user/root | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# sudo -u hadoop hadoop-0.20 fs -chown root /user/root | |||||||||||||||||||||||||||||||||||||||||||||||||||
| 作成したディレクトリを確認してみます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# sudo -u hadoop hadoop-0.20 fs -ls / | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Found 2 items | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxr-xr-x - hadoop supergroup 0 2010-04-19 22:47 /tmp | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxr-xr-x - hadoop supergroup 0 2010-04-22 06:00 /user | |||||||||||||||||||||||||||||||||||||||||||||||||||
| !コメント! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Franz160自身の/(ルート)ディレクトリ配下ではないことに注意してください。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| あくまでも、HDFS上の/(ルート)ディレクトリ配下をlsにて参照しています。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# sudo -u hadoop hadoop-0.20 fs -ls /user | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Found 2 items | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxr-xr-x - hadoop supergroup 0 2010-04-20 01:14 /user/hadoop | |||||||||||||||||||||||||||||||||||||||||||||||||||
| drwxr-xr-x - root supergroup 0 2010-04-22 06:00 /user/root | |||||||||||||||||||||||||||||||||||||||||||||||||||
| L-2.作業用ディレクトリを作成 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| HDFS上のroot用ディレクトリ配下に作業ディレクトリを作成してみます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# hadoop-0.20 fs -mkdir sonata | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# | |||||||||||||||||||||||||||||||||||||||||||||||||||
| !コメント! | |||||||||||||||||||||||||||||||||||||||||||||||||||
| HDFS上でchownを実施しているため、 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ここからはhadoopを実行する際にsudoを使わなくてもOKです。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| L-3.作業用ディレクトリにファイルをアップする | |||||||||||||||||||||||||||||||||||||||||||||||||||
| まずはアップするファイルをローカルに作成してみます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# cat << EOF > /var/tmp/Pathetique | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > Piano Sonata No.8 Pathetique | |||||||||||||||||||||||||||||||||||||||||||||||||||
| > EOF | |||||||||||||||||||||||||||||||||||||||||||||||||||
| L-4.HDFS上の/user/root/sonata配下にローカルファイルをアップします。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# hadoop-0.20 fs -put /var/tmp/Pathetique sonata | |||||||||||||||||||||||||||||||||||||||||||||||||||
| L-5.アップしたファイルを確認します。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# hadoop-0.20 fs -ls /user/root/sonata | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Found 1 items | |||||||||||||||||||||||||||||||||||||||||||||||||||
| -rw-r--r-- 10 root supergroup 29 2010-04-22 06:24 /user/root/sonata/Pathetique | |||||||||||||||||||||||||||||||||||||||||||||||||||
| L-6.アップしたファイルの内容を確認 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| ローカルに作成したファイルと同内容であることが確認できます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# hadoop-0.20 fs -cat sonata/Pathetique | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Piano Sonata No.8 Pathetique | |||||||||||||||||||||||||||||||||||||||||||||||||||
| L-7.ファイルの取り出し | |||||||||||||||||||||||||||||||||||||||||||||||||||
| HDFS上のファイルをローカルに取り出してみます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# hadoop-0.20 fs -get sonata/Pathetique /var/tmp/Pathetique2 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| L-8.取り出したファイルに相違ないかを確認してみます。 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| [root@Franz160 ~]# cat /var/tmp/Pathetique2 | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Piano Sonata No.8 Pathetique | |||||||||||||||||||||||||||||||||||||||||||||||||||